Trapped Ions Just Caught Up With Superconductors on the Hard Part of Error Correction

The IonQ team ran nine different quantum error-correcting codes on a single 40-ion device without touching the hardware between experiments. On one code that matched a published superconducting result qubit-for-qubit, they cut the logical error rate by a factor of four for one error type and nine for another. Several of their logical qubits lived as long as the physical qubits beneath them.
Why This Result Is Worth Your Attention
For years the surface code has been the safe bet in fault-tolerant quantum computing. It sits on a flat grid, talks only to neighbors, and several teams have built it. Google pushed it past breakeven in 2024, meaning their encoded qubit outlived its physical parts. But the surface code has a cost that nobody likes to say out loud. Each logical qubit eats hundreds of physical ones to reach error rates low enough for useful work.
Quantum low-density parity-check codes attack that cost directly. They drop the rule that qubits only touch their neighbors. Instead, each qubit talks to a fixed, small number of others, even ones across the chip. The payoff is that one block of physical qubits can hold many more logical qubits. Simulations have suggested qLDPC codes beat the surface code on overhead for a while now. The trouble was always building them, because those non-local connections demand wiring that most hardware can’t supply.
That’s what makes the IonQ paper, posted to arXiv as 2606.06455, interesting. The team at IonQ didn’t redesign their machine to fit one code. They picked codes that need wildly different connectivity and ran all of them on the same ion chain.
The Connectivity Problem Nobody Solved Cleanly
Here’s the thing about qLDPC codes on solid-state hardware. When Wang and colleagues demonstrated a bivariate bicycle code on superconducting qubits, they had to build custom “air-bridge” structures and tune Josephson junction resistances by hand, all to support one specific code. The chip was carpentry for a single floor plan. Change the code, rebuild the chip.
A trapped-ion machine sidesteps this. IonQ’s gates come from steerable Raman beams that can address any ion, or any pair of ions, in a stationary chain of forty barium-133 ions. No transport. Any qubit can entangle with any other. So the gate patterns that a qLDPC code, a toric code, and a concatenated code each demand, patterns that look nothing alike, all run on the same physical layout. The authors call this remarkable, and they’re right to. The flexibility isn’t a side benefit. It’s the whole reason the experiment exists.
They went further and used that freedom to assign qubits to ions intelligently. Not every ion pair gives the same two-qubit gate fidelity. By mapping the busiest gates onto the best-performing ion pairs, they raised average gate quality with zero change to hardware, calibration, or circuit structure. For most codes that trick cut the mean gate infidelity by a third to a half.
Measuring Qubits Mid-Circuit Without Wrecking the Rest
Error correction needs you to read ancilla qubits over and over while the circuit runs. On many trapped-ion systems this means physically shuttling ions around or carrying along a separate species of ion just for cooling. Both options burn time and qubits. In some machines half the ions exist only to cool the chain, and transport plus cooling can swallow most of the runtime.
IonQ used the optical-metastable-ground architecture, or OMG, to read ancillae in place. The idea moves a qubit between different energy manifolds inside a single ion rather than moving the ion through space. They shelve the whole chain into a metastable state that ignores small magnetic field wobble. Then they pull just the ancillae back down, read them, and use those same ancillae to cool the chain through sympathetic cooling. No dedicated coolant ions. No co-trapping two atomic species, which is a genuine engineering headache.
To my knowledge this is the first time the full OMG architecture has run in a working trapped-ion computer at this scale. Pieces of it had appeared before in one or two ions. Here it operates across enough qubits, with enough fidelity, to actually do error correction.
One more detail matters. When the readout detects a leaked qubit, IonQ throws out that shot rather than fixing it. That’s post-selection, and it raises an honest question about scaling, since rejection rates climbed to 74.8 percent for their most demanding code at six syndrome cycles. The authors address this head-on. They simulated the alternative, where a leaked qubit gets reset and re-initialized instead of discarded. Doing so degraded the logical error rate by only 10 to 17 percent. So the leakage they’re rejecting isn’t secretly carrying the whole result.
The Numbers
The headline comparison is a BB5 code encoding 4 logical qubits into 18 physical ones, matched against the superconducting BB6 code with the same 18-and-4 split.
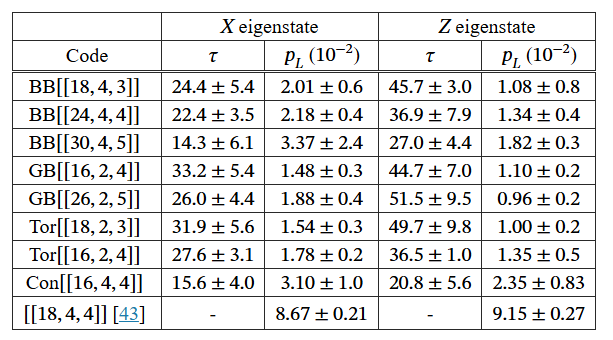
The superconducting code sat near 9 percent logical error per qubit per cycle in both bases. IonQ’s comparable code landed at 2.01 and 1.08 percent. That’s the four-times and nine-times improvement.
Living As Long As The Physical Qubits
The lifetime comparison is the part that earns the word breakeven. IonQ measured physical qubit coherence at T₂* ≈ 1.1 ± 0.3 seconds and an overall physical lifetime of 3.3 ± 0.9 seconds under their channel definition. Several logical qubits matched that within error bars. The GB [[26,2,5]] code reached a logical lifetime of 3.95 ± 0.68 seconds, slightly above the physical number.
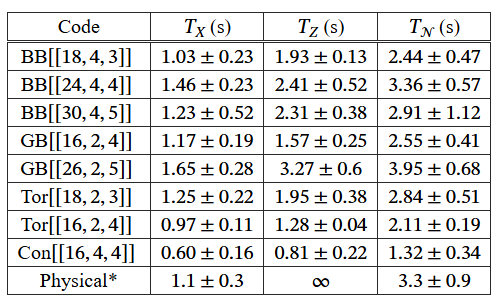
The concatenated code is the exception, and the authors don’t hide it. Its weight-8 checks make for a circuit that isn’t fault-tolerant, and its lifetime sits well below the rest. That’s the trade you accept with concatenation, which buys distance at the cost of encoding rate.
A note on the comparison method. IonQ adapted Google’s lifetime definition but made a different assumption when fitting the noise channel. Google set one noise parameter to zero, which produces a pessimistic estimate. IonQ instead set two parameters equal to each other, reflecting the actual bias on their device where phase errors dominate bit-flip errors. They checked this choice against their own simulations. It’s a reasonable call, though anyone comparing across platforms should keep the difference in mind. [LINK: comparing quantum hardware platforms]
What I’d Watch Next
The clearest limitation right now is speed. Gates run strictly one after another on this machine, even when the code structure would allow several at once. The cycle times in the paper run from 35 to 86 milliseconds, which is slow compared to where this needs to go. IonQ names two paths forward. More Raman zones would let more gates and shelving operations happen in parallel. Electronic qubit control is the more scalable route, and it pairs with recently demonstrated trapped-ion gates above 99.99 percent fidelity. They also point out that dynamical decoupling, which they didn’t use here, would lift both physical and logical coherence.
The post-selection question won’t go away on its own either. At small scale, discarding shots with detected leakage is fine. At the scale of a real fault-tolerant machine, those rejection rates would be fatal. The simulated erasure-conversion result is encouraging, but I want to see it run on hardware before calling the problem closed.
The reason qLDPC codes stayed theoretical for so long was the gap between what the codes need and what the hardware offers. Solid-state systems can hit very low gate errors but struggle with the long-range connections. IonQ’s chain gives both high gate fidelity and the connectivity these codes demand, on one device, without rebuilding anything. That combination is exactly what a qubit-efficient fault-tolerant architecture would require. This isn’t the finished machine. It’s a credible demonstration that the hard structural problem has a real answer.